New Advanced OCR Endpoint

.png)
Before, users weren't able to get or alter text from certain document formats like scans, images, or PDFs. They would have to transcribe every word into a format document that allowed them to edit or extract text, like a Word document (.docx). But OCR technology has changed the way documents are managed. There's no need to manually extract, edit, search, and count words from images, scans, or even PDFs anymore. Instead, OCR does it all for you.
But you're probably wondering why another PDF OCR if we already have one. Well, our basic PDF OCR endpoint serves its purpose: to extract raw text from PDFs. However, by partnering with natif.ai, we had the chance to optimize this endpoint. In this blog, we'll give you a glance at what this new endpoint is capable of.
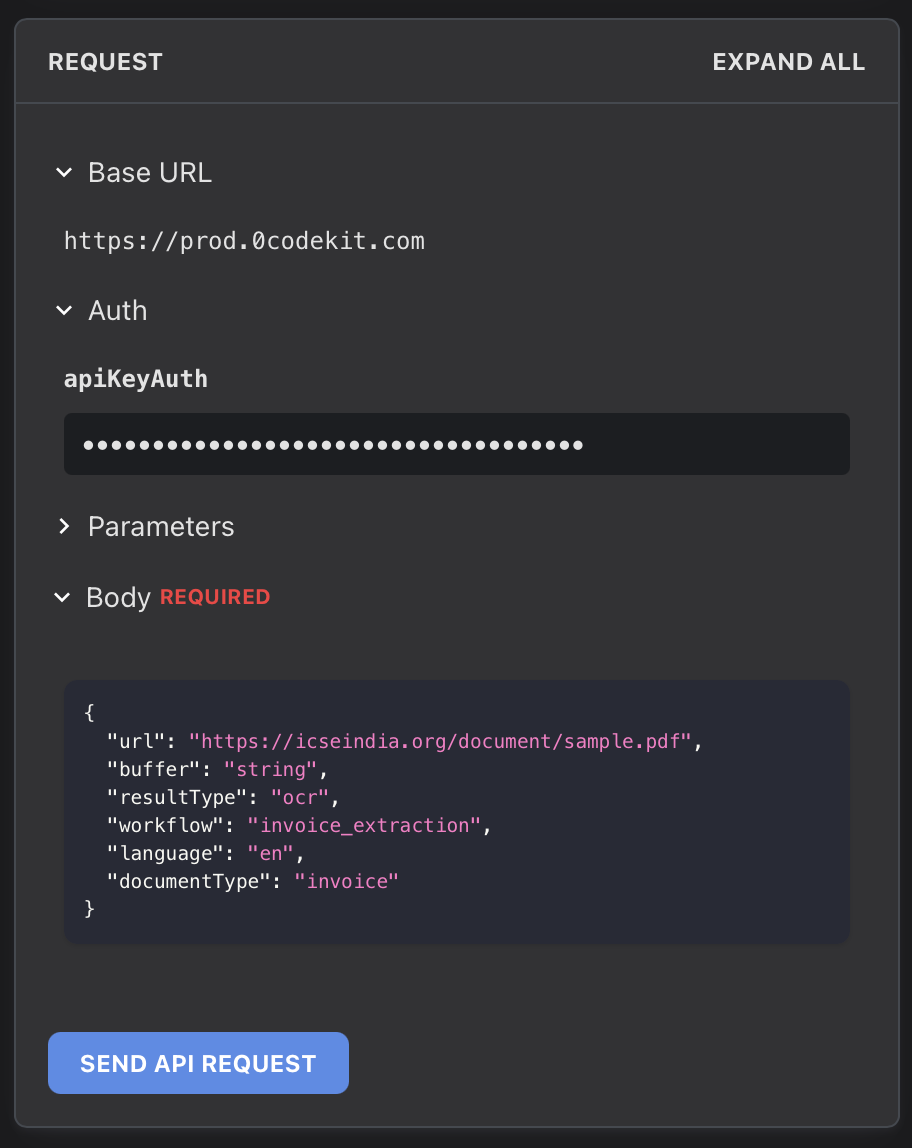
Our Advanced PDF OCR is not limited to text extraction. The main difference between the basic PDF OCR and this one is the response. Our basic PDF OCR extracts the text found in the document and returns just a block of text that, later, users would have to read through to find what they are looking for and sort the information depending on what they need. In contrast, the Advanced OCR returns structured data. When configuring the endpoint, it will ask you to specify the document type, and once it is defined, users can specify which fields they need.
For example, a user would like to extract the content of an invoice. He or she can specify which fields are to be extracted, such as the invoice number, invoice date, name and contact of the seller, name and contact of the buyer, product details, total sum, etc. Moreover, users can choose between two result types: OCR and Extraction. On one hand, OCR identifies and converts embedded or handwritten text from static document formats. On the other hand, extraction retrieves specific information or fields within the text.
But that's not all. Another feature of the Advanced OCR is that it can give the user specific information about the words found in the text. We have used a technique called "bounding box", which, in this case, defines the precise coordinates of a word or character in a document. In other words, this feature helps users find the exact location of a word or character on a page, which saves people from skimming through pages and blocks of text.
Moreover, the Advanced OCR comes with pre-configured templates. This endpoint has been trained to automatically identify and extract information from important fields on different types of documents. Here's a list of standard documents that the Advanced PDF OCR makes available to all users:
and many more!
But what if you cannot find a template that fits your documents? Or if your documents are more complex than the standard ones? For users who are constantly analyzing documents with a consistent structure, we can train a natif.ai model to be excellent at analyzing particular documents – a model just for you.
For this, we would only need some samples of the documents that are going to be frequently analyzed. From there, we can proceed to develop the workflow and train the natif.ai model to detect the fields that the user requires. Once trained, we would give the user an ID that he or she can use whenever the endpoint is used to analyze these or similar documents. That easy!